
Webseiten-URL-Extraktor
Ein Tool zur Extraktion und Darstellung aller Links von einer angegebenen Webseite, einschließlich Filterung und übersichtlicher Darstellung.
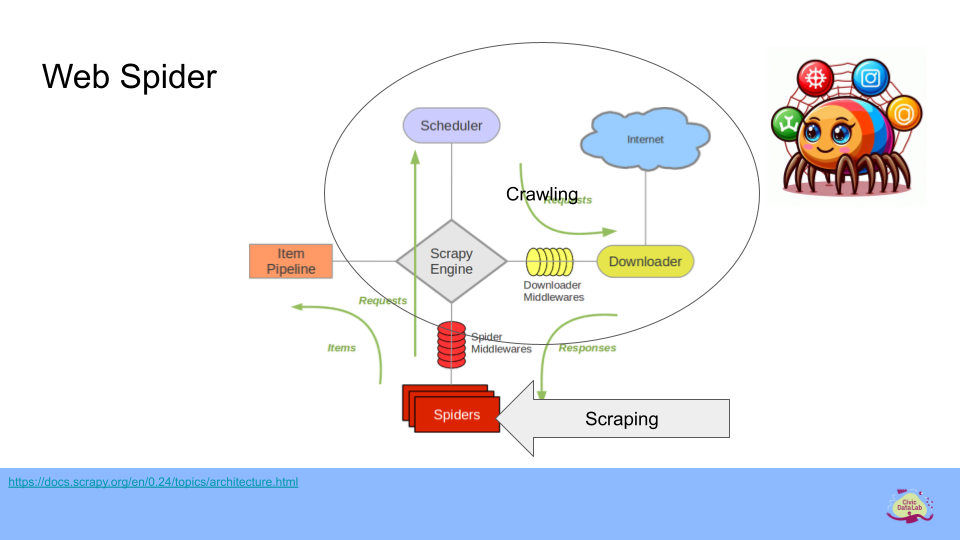
Das erste Bild illustriert die Funktionsweise eines Web Spiders oder Webscrapers mit dem Scrapy Framework. Hierbei wird der Prozess des Webcrawlings und -scrapings in mehreren Schritten dargestellt.
.png)
Das Bild zum Webcrawling zeigt einen Baumdiagramm, der die strukturelle Navigation durch eine Website veranschaulicht. Hierbei handelt es sich um einen Startpunkt (Startseite), von dem aus verschiedene Projektseiten (z.B. “Projekt 1”, “Projekt 2”, “Projekt 3”… “Projekt D”) und deren Details (z.B. “Details Projekt 1”, “Details Projekt A” usw.) durch einen Webcrawler systematisch durchsucht werden. Der Webcrawler folgt dabei Links von einer Seite zur nächsten und sammelt Informationen. Dies geschieht typischerweise, um Daten für Suchmaschinenindizes zu sammeln oder um Inhalte zu analysieren.
Insgesamt zeigen die Bilder die Systematik und den Ablauf von Webspider- und Webscraping-Techniken, die sowohl für das Durchsuchen (Crawling) als auch für das gezielte Extrahieren (Scraping) von Daten eingesetzt werden.
